Automatische collatie van literair-historische teksten
Collatie, een belangrijke stap in het editiewetenschappelijke onderzoek, behelst het vergelijken van twee of meer versies van een werk. Doel van dit project is enerzijds het reflecteren op het collatieproces, waarbij we ons bezig houden met vragen als “hoe definiëren we ’tekstuele variatie’?” en “wat zijn de methodologische consequenties van het automatiseren van deze belangrijke stap in tekstonderzoek?” Deze en soortgelijke onderzoeksvragen werken we uit in theoretische bijdragen en door het maken van (prototype) collatietools. Hieronder valt de tool CollateX, die is ontwikkeld in 2011 en wordt gebruikt door veel internationale editie-projecten.
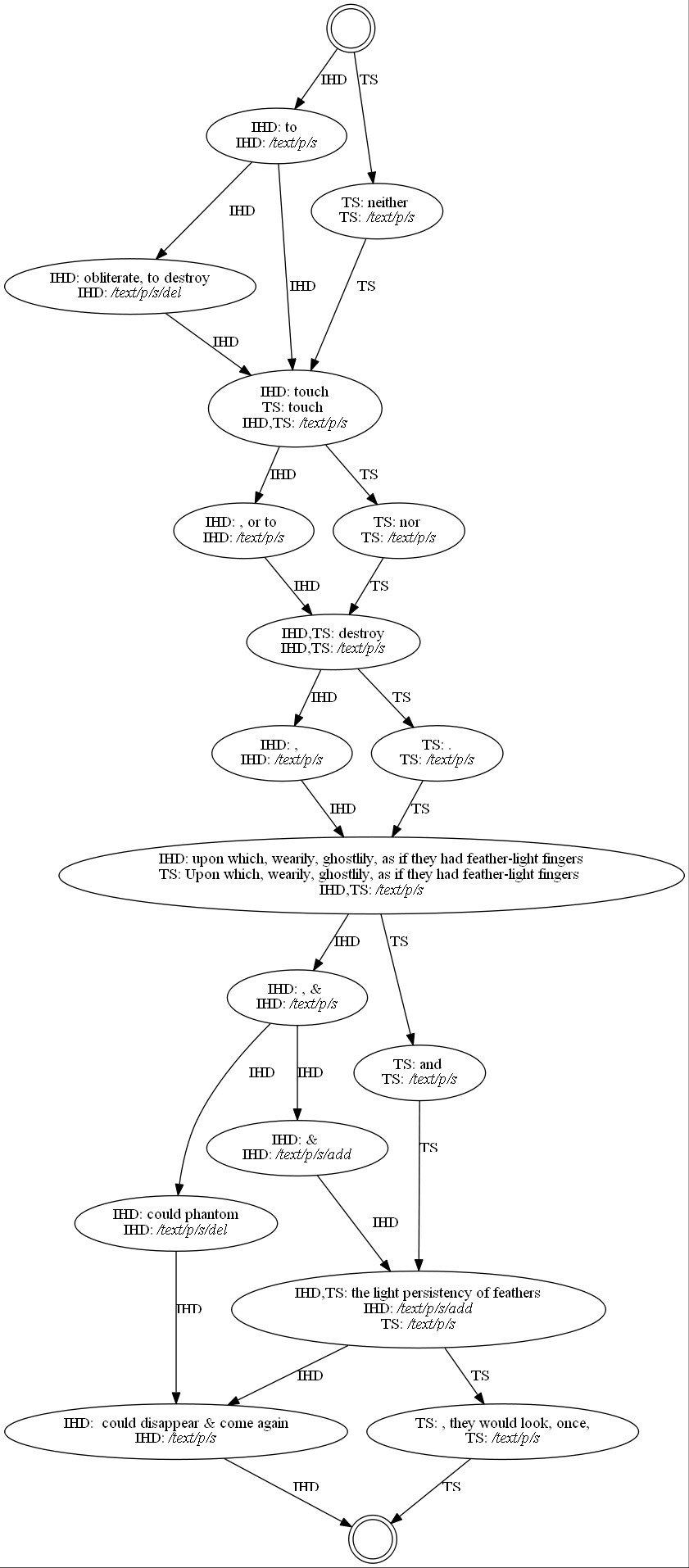
Daarnaast werken we aan het doorontwikkelen van de geavanceerde collatiesoftware HyperCollate waarbij bepaalde informatie in de markup wordt
gebruikt om variatie binnen één tekstgetuige (zoals doorhalingen of toevoegingen) ook mee te nemen in de tekstvergelijking. Op deze manier krijgen onderzoekers een beter en meer gedetailleerd inzicht in de tekstvariatie. Een belangrijk onderdeel van dit project is onderzoeken hoe collatiesoftware langere teksten kan verwerken. Ook moet de volgorde waarop tekstgetuigen worden ingevoerd geen invloed hebben op het collatieresultaat. Dit zijn twee complexe problemen waar wetenschappers al langer mee worstelen, en het oplossen ervan zal een belangrijke stap betekenen voor het vakgebied.
Tot slot houdt het project zich bezig met de uitdaging: hoe visualiseer je een dergelijk gedetailleerd collatieresultaat?